Hola,
En esta entrada, os explicaré como crear con Azure Functions, un test de disponibilidad de una URL y/o servicio publicado. El servicio no ha estar publicado en Azure.
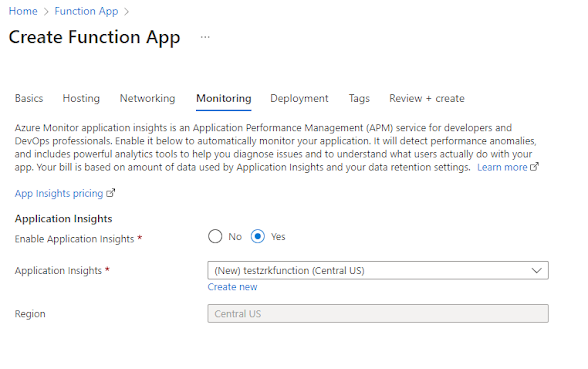
En primer lugar, crearemos un Function App, según veis en la captura siguiente:
En la ventana siguiente, Hosting, podremos crear el almacenamiento en el que se apoyará.
Y lo más importante, en monitoring tenéis que crear un Application Insights con el nombre de vuestro function.
A continuación, podréis crearlo.
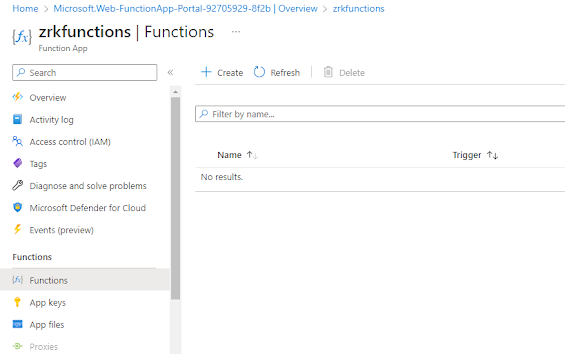
El siguiente paso, será ir a ir a Functions en el menú de la izquierda y crear uno nuevo:
En la creación, elegiremos una plantilla del tipo "Timer trigger":
Una vez creado, vea a App Service Editor en las opciones de desarrollo, dentro del Function creado:
Allí has de crear y modificar los siguientes archivos:
En TimerTrigger1, botón derecho crear function.proj con el siguiente contenido:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>netstandard2.0</TargetFramework>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.ApplicationInsights" Version="2.15.0" /> <!-- Ensure you’re using the latest version -->
</ItemGroup>
</Project>
Ahora crear el archivo RunAvailabilityTest.csx con el contenido siguiente (Cambiando www.google.com por la url a monitorizar:
using System.Net.Http;
public async static Task RunAvailabilityTestAsync(ILogger log)
{
using (var httpClient = new HttpClient())
{
// TODO: Replace with your business logic
await httpClient.GetStringAsync("https://www.google.com/");
}
}
Y ahora, reemplaza el contenido de run.csx por el siguiente contenido, indicando en REGION_NAME la región desde donde quieres que se realice el sondeo a la url.
#load "runAvailabilityTest.csx"
using System;
using System.Diagnostics;
using Microsoft.ApplicationInsights;
using Microsoft.ApplicationInsights.Channel;
using Microsoft.ApplicationInsights.DataContracts;
using Microsoft.ApplicationInsights.Extensibility;
private static TelemetryClient telemetryClient;
public async static Task Run(TimerInfo myTimer, ILogger log, ExecutionContext executionContext)
{
if (telemetryClient == null)
{
// Initializing a telemetry configuration for Application Insights based on connection string
var telemetryConfiguration = new TelemetryConfiguration();
telemetryConfiguration.ConnectionString = Environment.GetEnvironmentVariable("APPLICATIONINSIGHTS_CONNECTION_STRING");
telemetryConfiguration.TelemetryChannel = new InMemoryChannel();
telemetryClient = new TelemetryClient(telemetryConfiguration);
}
string testName = executionContext.FunctionName;
string location = Environment.GetEnvironmentVariable("REGION_NAME");
var availability = new AvailabilityTelemetry
{
Name = testName,
RunLocation = location,
Success = false,
};
availability.Context.Operation.ParentId = Activity.Current.SpanId.ToString();
availability.Context.Operation.Id = Activity.Current.RootId;
var stopwatch = new Stopwatch();
stopwatch.Start();
try
{
using (var activity = new Activity("AvailabilityContext"))
{
activity.Start();
availability.Id = Activity.Current.SpanId.ToString();
// Run business logic
await RunAvailabilityTestAsync(log);
}
availability.Success = true;
}
catch (Exception ex)
{
availability.Message = ex.Message;
throw;
}
finally
{
stopwatch.Stop();
availability.Duration = stopwatch.Elapsed;
availability.Timestamp = DateTimeOffset.UtcNow;
telemetryClient.TrackAvailability(availability);
telemetryClient.Flush();
}
}
Ahora podrás ir a la opción Availability del application insights creado y monitorizar la disponibilidad del servicio: